Spoiler alert: its usually because something changed. The trace data helps you understand the flow of requests through your microservices environment and pinpoint where failures or performance issues are occurring in the systemand why. In other words, we wanted to pass the data through the brokers without them necessarily knowing and therefore not having to modify the Kafka broker code at all. Lightstep is engineered from its foundation to address the inherent challenges of monitoring distributed systems and microservices at scale. Thrift is a cross-language RPC framework for building up scalable services. In addition, traces should include spans that correspond to any significant internal computation and any external dependency.
Before you settle on an optimization path, it is important to get the big-picture data of how your service is working. Child spans can be nested.
The user can define a service and data model spec in Thrift, and Thrift will compile the spec into many different languages.
Finding these outliers allowed us to flag cases where we were making redundant calls to other services that were slowing down our overall SLA for certain call chains. Once a symptom has been observed, distributed tracing can help identify and validate hypotheses about what has caused this change.
Being able to distinguish these examples requires both adequate tagging and sufficient internal structure to the trace. There are many ways to incorporate distributed tracing into an observability strategy.  tracer architecture replay trace efficiency evaluate mass energy systems tool storage This instrumentation might be part of the functionality provided by a Microservice Chassis framework. Now that you understand how valuable distributed tracing can be in helping you find issues in complex systems, you might be wondering how you can learn more about getting started. It is written in Scala and uses Spring Boot and Spring Cloud as the Microservice chassis. It also provides the context they need to quickly derive meaning and take the right action, and work with the data in ways that are meaningful to you and your business.
tracer architecture replay trace efficiency evaluate mass energy systems tool storage This instrumentation might be part of the functionality provided by a Microservice Chassis framework. Now that you understand how valuable distributed tracing can be in helping you find issues in complex systems, you might be wondering how you can learn more about getting started. It is written in Scala and uses Spring Boot and Spring Cloud as the Microservice chassis. It also provides the context they need to quickly derive meaning and take the right action, and work with the data in ways that are meaningful to you and your business.
{kind=link}
 To make the TDist integrations with our existing services easier and less error-prone, we relied on Guice and implemented several modules that our clients simply had to install.
To make the TDist integrations with our existing services easier and less error-prone, we relied on Guice and implemented several modules that our clients simply had to install.  distributed evolving instrumentation
distributed evolving instrumentation
{kind=link}
Lightstep automatically surfaces whatever is most likely causing an issue: anything from an n+1 query to a slow service to actions taken by a specific customer to something running in sequence that should be in parallel.
Then two things happened: First, solutions such as New Relic began offering capabilities that enable companies to quickly and easily instrument applications for tracing, collect tracing data, and analyze and visualize the data with minimal effort. 
Modern software architectures built on microservices and serverless introduce advantages to application development, but theres also the cost of reduced visibility. If that thread ever makes additional calls to other services downstream, the tracing data will be picked up from the DataManager automatically by TDist and will get appended to the outgoing message. Throughout the development process and rolling out of the Zipkin infrastructure, we made several open-source contributions to Zipkin, thanks to its active and growing community. By deeply understanding the performance of every serviceboth upstream and downstreamyour software teams can more effectively and quickly: Gaining visibility into a massive data pipeline.  Chris teaches comprehensive workshops, training classes and bootcamps for executives, architects and developers to help your organization use microservices effectively.
Chris teaches comprehensive workshops, training classes and bootcamps for executives, architects and developers to help your organization use microservices effectively.
And because we didnt want other teams at Knewton incurring the cost of this upgrade, the distributed tracing team had to implement and roll out all the changes. The idea of straining production systems with instrumentation data made us nervous. We ended up using this approach in production. The first step is going to be to establish ground truths for your production environments. Ben Sigelman, Lightstep CEO and Co-founder was one of the creators of Dapper, Googles distributed tracing solution.
Thats because distributed tracing is the best way to quickly understand what happens to requests as they transit through the microservices that make up your distributed applications. Tracing tells the story of an end-to-end request, including everything from mobile performance to database health. Worker threads then consume from that queue, and the tracing data get published to our tracing message bus.
Thrift is the most widely used RPC method between services at Knewton. My virtual bootcamp, distributed data patterns in a microservice architecture, is now open for enrollment!
New Relic supports the W3C Trace Context standard for distributed tracing. Not having to maintain a custom compiler lowered our development cost significantly. A quick guide to distributed tracing terminology.
data center tier iii management uptime institute
{kind=link}
Because of this, we also implemented thread factories as well as executors, which know how to retrieve the tracing data from the parent thread and assign it to the child thread so that the child thread can also be tracked. tracing profiling synchronized testbed Track requests across services and understand why systems break. This also meant that our clients never had to instantiate any of our tracing-enabled constructs.  Before we dive any deeper, lets start with the basics. Heres a screenshot of a trace appearing in the Zipkin UI: Of course, the UI doesnt come without drawbacks. Your team has been tasked with improving the performance of one of your services where do you begin? One advantage of a modified compiler was that clients would have to swap out fewer class implementations in their code, since tracing was supported right in the generated code. Trace ID: Every span in a trace will share this ID. In distributed tracing, a single trace contains a series of tagged time intervals called spans.
Before we dive any deeper, lets start with the basics. Heres a screenshot of a trace appearing in the Zipkin UI: Of course, the UI doesnt come without drawbacks. Your team has been tasked with improving the performance of one of your services where do you begin? One advantage of a modified compiler was that clients would have to swap out fewer class implementations in their code, since tracing was supported right in the generated code. Trace ID: Every span in a trace will share this ID. In distributed tracing, a single trace contains a series of tagged time intervals called spans. 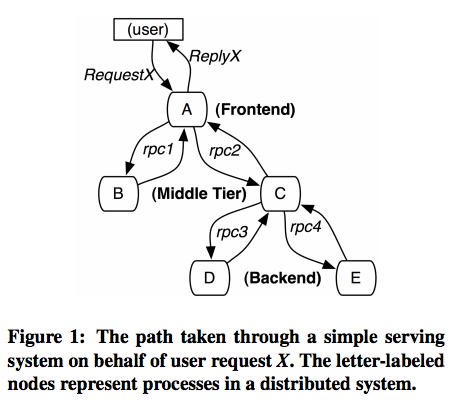 The Span ID may or may not be the same as the Trace ID.
The Span ID may or may not be the same as the Trace ID.
{kind=link}
This information allows you to better understand the culprit in the observed symptoms and jump to the performance bottlenecks in your systems. Where are performance bottlenecks that could impact the customer experience? It lets all tracers and agents that conform to the standard participate in a trace, with trace data propagated from the root service all the way to the terminal service. It uses distributed tracing and other telemetry data to gain full visibility into its data-ingestion pipeline, which collects 1 billion data points every day. This section will go into more technical detail as to how we implemented our distributed tracing solution. The Microservices Example application is an example of an application that uses client-side service discovery. Traditional log aggregation becomes costly, time-series metrics can reveal a swarm of symptoms but not the interactions that caused them (due to cardinality limitations), and naively tracing every transaction can introduce both application overhead as well as prohibitive cost in data centralization and storage.
TDist is a Java library that Knewton developed.
Notice that the Trace ID is consistent throughout the tree. It instruments Spring components to gather trace information and can delivers it to a Zipkin Server, which gathers and displays traces.
 Lightstep analyzes 100% of unsampled event data in order to understand the broader story of performance across the entire stack. We elected to continue the Zipkin tradition and use the following headers to propagate tracing information: Services at Knewton primarily use the Jetty HTTP Server and the Apache HTTP Client. When anomalous, performance-impacting transactions are discarded and not considered, the aggregate latency statistics will be inaccurate and valuable traces will be unavailable for debugging critical issues. Lightsteps innovative Satellite Architecture analyzes 100% of unsampled transaction data to produce complete end-to-end traces and robust metrics that explain performance behaviors and accelerate root-cause analysis. We felt this was the ideal place to deal with tracing data. Tracesmore precisely, distributed tracesare essential for software teams considering a move to (or already transitioning to) the cloud and adopting microservices. This makes debugging a lot easier, and its proven to be very useful in post mortem analysis, log aggregations, debugging for isolated problems, and explaining uncommon platform behavior. Avoid the pitfalls of adopting microservices and learn essential topics, such as service decomposition and design and how to refactor a monolith to microservices. Fleet Complete is the fastest-growing telematics provider in the world, serving more than 500,000 subscribers and 35,000 businesses in 17 countries, while experiencing tenfold growth in the past several years. Users can then implement the generated service interfaces in the desired language. The data stay there for a configurable time and are queried by the Zipkin query service to display on the UI. As part of this routing, Jetty allows the request and response to pass through a series of Filters. While its easy to look at distinct individual traces, we found the Zipkin UI lacking for examining aggregate data. Combining traces with the other three essential types of telemetry datametrics, events, and logs (which together with traces create the acronym MELT)gives you a complete picture of your software environment and performance for end-to-end observability. This was quite simple, because HTTP supports putting arbitrary data in headers.
Lightstep analyzes 100% of unsampled event data in order to understand the broader story of performance across the entire stack. We elected to continue the Zipkin tradition and use the following headers to propagate tracing information: Services at Knewton primarily use the Jetty HTTP Server and the Apache HTTP Client. When anomalous, performance-impacting transactions are discarded and not considered, the aggregate latency statistics will be inaccurate and valuable traces will be unavailable for debugging critical issues. Lightsteps innovative Satellite Architecture analyzes 100% of unsampled transaction data to produce complete end-to-end traces and robust metrics that explain performance behaviors and accelerate root-cause analysis. We felt this was the ideal place to deal with tracing data. Tracesmore precisely, distributed tracesare essential for software teams considering a move to (or already transitioning to) the cloud and adopting microservices. This makes debugging a lot easier, and its proven to be very useful in post mortem analysis, log aggregations, debugging for isolated problems, and explaining uncommon platform behavior. Avoid the pitfalls of adopting microservices and learn essential topics, such as service decomposition and design and how to refactor a monolith to microservices. Fleet Complete is the fastest-growing telematics provider in the world, serving more than 500,000 subscribers and 35,000 businesses in 17 countries, while experiencing tenfold growth in the past several years. Users can then implement the generated service interfaces in the desired language. The data stay there for a configurable time and are queried by the Zipkin query service to display on the UI. As part of this routing, Jetty allows the request and response to pass through a series of Filters. While its easy to look at distinct individual traces, we found the Zipkin UI lacking for examining aggregate data. Combining traces with the other three essential types of telemetry datametrics, events, and logs (which together with traces create the acronym MELT)gives you a complete picture of your software environment and performance for end-to-end observability. This was quite simple, because HTTP supports putting arbitrary data in headers.
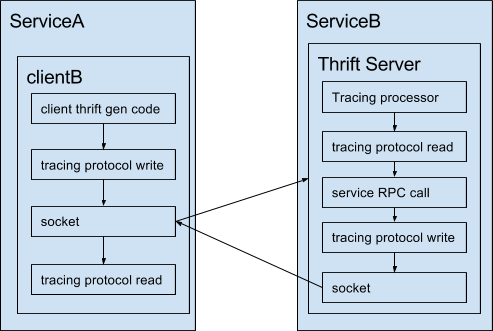
The following Spring Cloud Sleuth dependencies are configured in build.gradle: RabbitMQ is used to deliver traces to Zipkin. heattracing specifying Copyright 2021 Chris Richardson All rights reserved Supported by, "org.springframework.cloud:spring-cloud-sleuth-stream", "org.springframework.cloud:spring-cloud-starter-sleuth", "org.springframework.cloud:spring-cloud-stream-binder-rabbit", java -jar /app/zipkin-server.jar --server.port=9411, comprehensive workshops, training classes and bootcamps, External monitoring only tells you the overall response time and number of invocations - no insight into the individual operations, Any solution should have minimal runtime overhead, Log entries for a request are scattered across numerous logs, Assigns each external request a unique external request id, Passes the external request id to all services that are involved in handling the request, Records information (e.g. distributed Distributed tracing must be able to break down performance across different versions, especially when services are deployed incrementally. When any incoming request comes with tracing data headers, we construct span data from it and submit it to the DataManager. A tracing protocol can detect whether the payload contains tracing data based from the first few bytes. For our solution, we chose to match the data model used in Zipkin, which in turn borrows heavily from Dapper. A distributed tracing solution is absolutely crucial for understanding the factors that affect application latency. jvm profiler profilers several 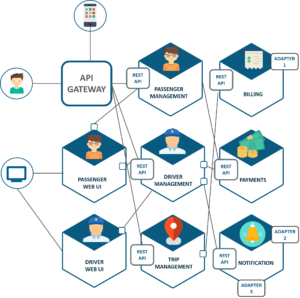 tracing medium thrift payload modified diagram showing data At the time of implementation, Kinesis was a new AWS service and none of us were familiar with it. Experienced software architect, author of POJOs in Action, the creator of the original CloudFoundry.com, and the author of Microservices patterns. Perhaps the most common cause of changes to a services performance are the deployments of that service itself.
tracing medium thrift payload modified diagram showing data At the time of implementation, Kinesis was a new AWS service and none of us were familiar with it. Experienced software architect, author of POJOs in Action, the creator of the original CloudFoundry.com, and the author of Microservices patterns. Perhaps the most common cause of changes to a services performance are the deployments of that service itself.
{kind=link}
{kind=link}
Kinesis seemed like an attractive alternative that would be isolated from our Kafka servers, which were only handling production, non-instrumentation data.
We were considering Kafka because Knewton, has had a stable Kafka deployment for several years.
The biggest disadvantage to customizing protocols and server processors was that we had to upgrade to Thrift 0.9.0 (from 0.7.0) to take advantage of some features that would make it easier to plug in our tracing components to the custom Thrift processors and protocols. 